
AI‑агенты уже умеют много, но в реальных проектах они часто «тупят» не потому, что модель слабая, а потому что мы неправильно с ними работаем. Даже с относительно недорогими моделями можно выполнять большую часть задач, если уметь работать с контекстом.
В этой статье я собрал самые частые ошибки, которые вижу у разработчиков (и у себя), когда мы подключаем AI‑агентов к живым задачам. Разберём, как передавать задачи, как настраивать контекст и инструменты, и что сделать, чтобы агент помогал, а не мешал.
Не претендую на строгое академическое исследование, это скорее практический взгляд, основанный, в том числе, на некоторых исследованиях.
Передавайте AI‑задачи, которые знаете, как решать
Чем лучше вы понимаете задачу, которую хотите решить, тем лучше эта задача подходит для того, чтобы передать её AI‑агенту.
Если вы чётко понимаете контекст, осознаёте последовательность решаемой задачи (декомпозиция важна для LLM) и можете провалидировать предлагаемое решение, то вы с наибольшей вероятностью получите нужный результат.
Просишь AI выполнить задачу, она снова и снова решает её не так, как тебе надо, и ты проходишь несколько итераций, пока не получится то, что надо, если вообще получится.
Если следовать этому правилу:
- Сможешь определить качество решения
- Понимая, какой контекст важен, сможешь лучше сформулировать задачу
- Меньше тратишь времени на корректировки в процессе работы с агентом
Слишком большой контекст
Больший контекст — не значит лучший результат. Наоборот, есть исследование, которое показывает, что чем меньше контекстное окно разрастается, тем ближе мы к ожидаемому решению.
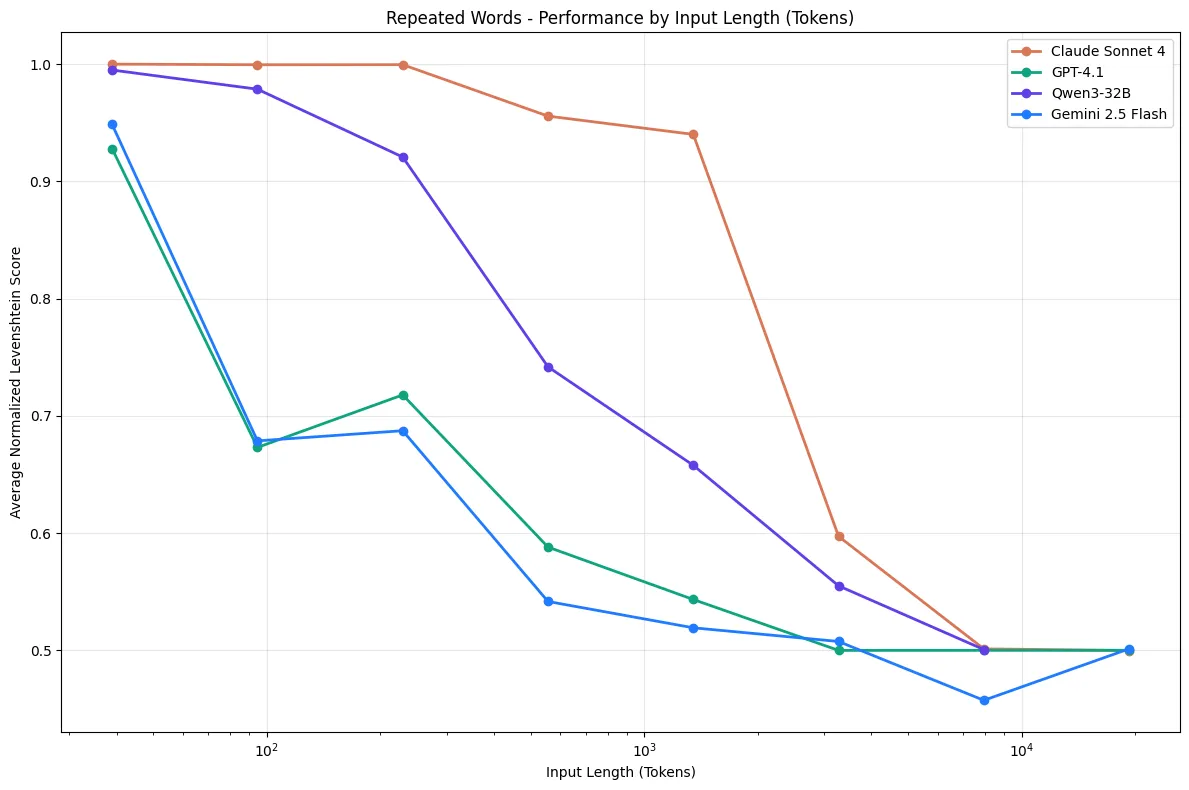
Claude Sonnet 4, GPT-4.1, Qwen3-32B, and Gemini 2.5 Flash on Repeated Words Task
У многих моделей качество может резко проседать на больших контекстах, особенно когда:
- вопрос не совсем прямой.
- вокруг есть похожий шум.
- контекст просто огромный.
Какой контекст можно считать излишним? Если отталкиваться от исследования1, выходит так, что выше ~100k+ токенов сильно деградирует качество.
Какие варианты решения?
- Сделать
compactв вашем AI‑агенте, чтобы он сделал краткое резюме по текущему контексту. Решение не идеально, некоторый важный контекст может теряться. - Попросить AI‑агента сделать заметку. Заметка о том, что уже сделано в рамках этой задачи, что
предстоит сделать и на что обращать внимание, затем выгрузить всю эту информацию в какой‑нибудь
@docs/HANDOFF.md. Далее создать новую сессию и ссылаться на этот файл для продолжения задачи. - Держите ключевые договорённости (правила/инструкции) в
AGENTS.md(характерно для Opencode), либо в любом другомmd‑файле, где принято описывать правила для вашего AI‑агента. Полезно, чтобы не потерять какие‑то важные правила, которым должен следовать AI‑агент.
Плохая работа с “памятью” агента
Что вообще такое “память” агента?
Память агента — это все то, что вы положили в качестве инструкций в репозитории проекта. Для OpenCode — это файл
AGENTS.MD, для Claude — это CLAUDE.MD.
- Какие правила важнее всего.
- Какие команды/проверки обязательны.
- Какой code style проекта.
- Какие грабли уже известны и как их обходить.
- Как правильно собирать и тестировать проект.
Если это работает — агент меньше тупит, меньше делает лишнего, меньше зацикливается на решении типовых для вашего проекта ошибок. Агент не запоминает свои ошибки, поэтому это наша работа дать ему все необходимые вводные.
Основные правила, которым я следую
- Обязательно пишем инструкции к проекту.
- Инструкции не должны быть слишком большими. Мы пишем не документацию, а набор инструкций, которым должен следовать AI‑агент.
- Актуализируем правила. Если при работе в проекте вы постоянно натыкаетесь на то, что агент уходит в одинаковые циклы для решения повторяющихся проблем — это хороший маркер того, что правило нужно вынести в инструкции.
Использование устаревших инструментов
Как мы начинали пользоваться LLM
AI‑инструментарий активно развивается. Если в начале пути мы писали чат‑ботам в ChatGPT/DeepSeek/Grok, получали код и копировали к себе в проект, то теперь мы доросли до AI‑агентов, и они тоже не стоят на месте. Условно, если вы год назад пробовали и разочаровались, то есть смысл дать шанс ещё раз.
- Развиваются модели, повышается их качество при решении разного рода задач. Раньше “болячки” моделей были куда более явные: хуже держали длинный контекст, чаще “додумывали”, хуже следовали формату, хуже работали с пошаговыми задачами (план → изменения → валидация).
- Агенты — это не то же самое, что чат‑бот. Агент — это рантайм‑оркестратор: он подключает инструменты и права, даёт LLM‑модели их интерфейсы, выполняет вызовы и возвращает результаты. LLM отвечает за выбор шагов и формирование запросов.
Поэтому, если раньше или до сих пор вы работаете только с чат‑ботом, то есть смысл пересесть на AI‑агентов.
Но даже если опустить тему сравнения агентов и чат‑ботов, активно меняются и сами AI‑инструменты, всё меняется так быстро, что не успеваешь изучить один, а в следующем месяце появляется новый. Когда‑нибудь эта “буря” уляжется, и с нами останется только самое проверенное временем. В таком потоке важно выделять именно то, что работает и работает лучше, чем то, что вы используете сейчас, чтобы не засиживаться на устаревшем.
Проблемы в среде разработки
Частая проблема при работе с AI‑агентами — это сломанная среда разработки. Например, чтобы собрать проект, нужна определённая последовательность неочевидных действий, которая вынуждает агента искать решение даже не основной задачи, с которой к нему пришли.
Некоторые примеры таких проблем:
- Сборка проекта требует определённой последовательности шагов, которая явно не задокументирована.
- Криво выстроен проект. Например, если для компиляции вашего проекта нужно зайти в определённую папку проекта и выполнить команду, чтобы его собрать, — это явная проблема в конфигурации проекта.
- Неправильно настроен linter. Если работа линтера зависит от того, как его запускать, — это проблема для агента. В том числе и для человека, который будет пытаться такой проект собрать.
Простое эмпирическое правило: стремитесь сделать ваш проект таким, чтобы любой человек без особых знаний контекста о нём
мог легко в нём работать. Если видите, что агент запинается на одинаковых проблемах — исправляйте проект, не пытайтесь
добавлять эти исключения в инструкции (AGENTS.md/CLAUDE.md).
Перегрузка контекста дополнительным инструментарием
Десятки MCP‑серверов на все случаи жизни, а по факту получаем хуже результат и увеличенный расход токенов. В итоге агент тратит время на выбор инструмента, делает лишние вызовы, гоняет лишние токены, чаще ошибается, разбухает контекст.
Выбирай только те MCP, которые закрывают какую‑то проблему. Используй точечно под определённую задачу, убедись, что эту задачу нельзя решить никак иначе. Чем меньше подобной конфигурации агента, тем лучше он работает.
Множество итераций для решения проблемы

Чем меньше итераций тем лучше результат
Это история про то, когда накидывают уточнения поверх прошлых выводов агента. LLM/агент воспринимает чат как последовательность фактов и решений. Если в первых шагах он неправильно понял задачу, выбрал неверную гипотезу, начал менять не те файлы и тому подобное, то наши дальнейшие корректировки только мешают в выполнении поставленной задачи.
Есть исследование2, где проверяли качество выполняемой задачи при пошаговом подходе: производительность протестированных моделей падает по сравнению с тем, когда задача выдаётся одним промптом, среднее падение ~39%.
Лучше сделать откат, когда заметили, что агент делает что‑то не то, и дополнить контекст задачи. Кроме того, важно использовать режим планирования (Plan), чтобы сначала ответить на все вопросы и лишь затем, собрав все артефакты, отдавать в работу.
Нечёткие запросы и отсутствие важного контекста
Писать агенту запросы вроде “помоги решить ошибку, она возникает в таком‑то файле” — непродуктивно. Чтобы лучше сформулировать свой запрос, я обычно следую таким правилам:
- Дополнять свой запрос любым полезным контекстом. Например, если вы знаете, в каком файле проблема, то расскажите, как вы вообще к этому пришли, какую проблему изначально решаете.
- Если есть логи, какие‑то конкретные ошибки, которые вы увидели, — это также обязательно нужно дополнить в запрос.
- Если вы уже имеете весь необходимый контекст и знаете, как проблему решать, то сразу используйте
Buildрежим. - Не браться за решение проблемы, которую вы сами не знаете, как решать.
Резюме
Если коротко, хорошие результаты от AI‑агента чаще всего упираются не в «силу модели», а в то, как мы организуем работу вокруг неё.
- Передавайте агенту задачи, в которых сами понимаете контекст и можете проверить результат.
- Не раздувайте контекст до сотен тысяч токенов, лучше делайте сжатие и выносите договорённости в отдельные файлы.
- Держите «память» проекта в инструкциях (
AGENTS.md/CLAUDE.md) и регулярно её обновляйте. - Следите за инструментами и средой разработки: используйте актуальные агенты и делайте проект предсказуемым для сборки.
- Не перегружайте агента MCP‑серверами и не тащите одну и ту же сессию через десятки итераций — лучше перезапустить с улучшённым промптом.
- Формулируйте запросы чётко, с логами, файлами и целями, а не одной фразой «почему не работает?».
Если относиться к AI‑агенту как к сильному, но забывчивому напарнику и помогать ему хорошими инструкциями и чистой средой, он начнёт экономить вам часы, а не забирать их.